HBase-zelfstudie: HBase-introductie en Facebook-casestudy
Deze HBase-zelfstudieblog laat u kennismaken met wat HBase en zijn functies is. Het behandelt ook de casestudy van Facebook Messenger om de voordelen van HBase te begrijpen.

Deze HBase-zelfstudieblog laat u kennismaken met wat HBase en zijn functies is. Het behandelt ook de casestudy van Facebook Messenger om de voordelen van HBase te begrijpen.
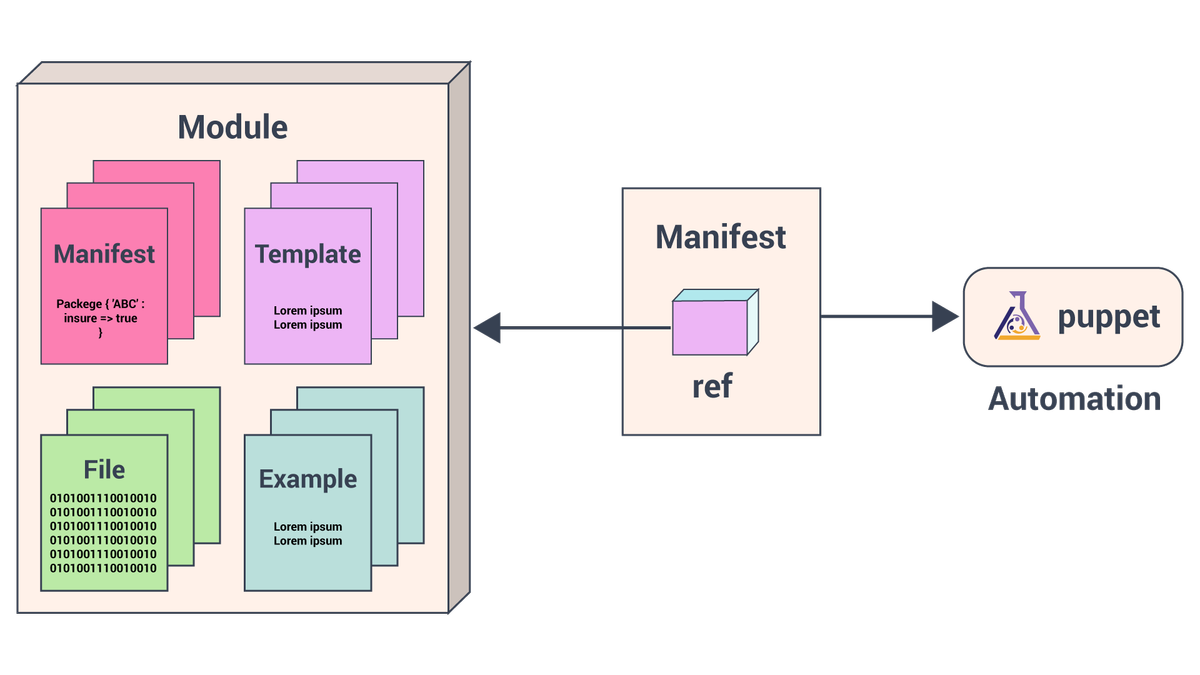
Deze blog is een handleiding voor het installeren van Puppet Master en Puppet Agent. Het bevat ook een voorbeeld om Apache Tomcat te implementeren met behulp van Puppet Tomcat Module.
Deze blog is een stapsgewijze handleiding voor de installatie van Apache Pig in een Linux-omgeving. We zullen Apache Pig 0.16.0 installeren en het in verschillende modi uitvoeren.
Deze blog over HBase Architecture legt het HBase Data Model uit en geeft inzicht in HBase Architecture. Het verklaart ook verschillende mechanismen in HBase.
Deze Hive-tutorialblog geeft je diepgaande kennis van Hive Architecture en Hive Data Model. Het verklaart ook de NASA-casestudy over Apache Hive.
Deze Spark Streaming-blog laat je kennismaken met Spark Streaming, de functies en componenten ervan. Het bevat een sentimentanalyseproject met behulp van Twitter.
Deze Spark MLlib-blog laat je kennismaken met de Machine Learning-bibliotheek van Apache Spark. Het bevat een Movie Recommendation System-project met Spark MLlib.
Deze GraphX Tutorial-blog laat je kennismaken met Apache Spark GraphX, zijn functies en componenten, waaronder een Flight Data Analysis-project.
Deze Apache Flume-tutorialblog legt de basisprincipes van Apache Flume en zijn functies uit. Het toont ook Twitter-streaming met Apache Flume.
Apache Sqoop-zelfstudie: Sqoop is een tool voor het overbrengen van gegevens tussen Hadoop en relationele databases. Deze blog behandelt de import en export van Sooop vanuit MySQL.
Apache Oozie-zelfstudie: Oozie is een workflowplannersysteem om Hadoop-taken te beheren. Het is een schaalbaar, betrouwbaar en uitbreidbaar systeem.
Big Data-applicaties brengen een revolutie teweeg in organisaties en helpen hen om meer informatieve zakelijke beslissingen te nemen door grote hoeveelheden gegevens te analyseren.
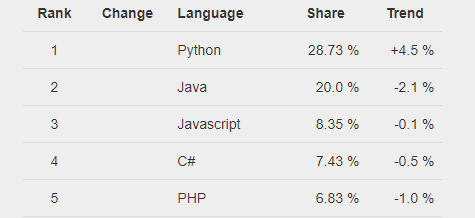
Apache Spark heeft de Big Data & Analytics-wereld overgenomen en Python is een van de meest toegankelijke programmeertalen die tegenwoordig in de industrie worden gebruikt. Dus hier in deze blog leren we over Pyspark (vonk met python) om het beste uit beide werelden te halen.
Deze blog richt zich op Apache Hadoop YARN dat werd geïntroduceerd in Hadoop versie 2.0 voor resource management en taakplanning. Het legt de YARN-architectuur uit met zijn componenten en de taken die door elk van hen worden uitgevoerd. Het beschrijft de indiening van applicaties en de workflow in Apache Hadoop YARN.
In deze blog over PySpark-zelfstudie leert u over PSpark API die wordt gebruikt om met Apache Spark te werken met behulp van Python-programmeertaal.
In deze PySpark Dataframe-zelfstudieblog leert u met meerdere voorbeelden over transformaties en acties in Apache Spark.
Deze Edureka-blog over Cloudera Hadoop-zelfstudie geeft je een compleet inzicht van verschillende Cloudera-componenten zoals Cloudera Manager, Parcels, Hue enz.
Dit bericht beschrijft de toename van de vraag naar Hadoop- en NoSQL-vaardigheden op IT en andere gebieden. lees verder om te zien hoe Hadoop- en NoSQL-vaardigheden kunnen helpen
Deze blog bespreekt de voordelen van Hadoop-implementatie, Hadoop-initiatieven, Hadoop in kleine en grote organisaties en carrièrevoordelen van Hadoop-training.
Hadoop is een populaire vaardigheid geworden die moet worden verworven in het IT-circuit, het profiel van Hadoop-leerlingen neemt met de dag drastisch toe.